【方案】使用redis hash和bitfield替换简单kv
时间:2018年12月-2019年3月
关键字:key-value,hash,bitfield,redis,节省内存
重点概括:
- 使用redis的hash和bitfield两种数据结构,将多个key-value对变成一个单一的数据结构存储,避免将key多次重复存储,大幅度减少占用内存空间;同时,也大幅度提高了业务侧的读写效率。
- 通过使用数字代码而非实际的字段名称,替换redis hash中的field,节省内存空间。
- 后端存储平均请求返回时长从39s下降为3s。
redis bitfield介绍:http://antirez.com/news/103
完整的测试及性能报告如下:
当前存储使用情况
目前消息列表的实时数据保存在CouchBase中,使用的是key-value的形式,即每一个指标都是一个key-value存储。这种情况,由于同一个key可能有多个指标(比如发送量、送达量、点击量,还区分IOS和安卓平台),所以同一个key会重复出现多次。
一个key需要占用30个bytes以上的存储,再加上CouchBase对每一个Document额外的56个bytes的metadata(参考这里:metadata),导致key+metadata占用超过60%的内存,内存使用效率低下。
增加一个指标的时候可能整体的数据又不断的暴涨。
并且每次iportal和report api读取一个msg_id的所有指标的时候,需要多次(最多达25次以上)访问CB,从而加剧了CB的负载,特别是最近一段时间,频繁出现故障。
目前现在正在用的有3个CB,2个正式使用的cb(realtime-stats<1.24T>和csc-msg-stats<468G>)和即将投产的cscstats-ptask(849G)。
测试过程及结论数据
基于上面种种问题和资源的不断膨胀。现在在调研redis hash结构,通过hincryBy操作来实现数据的存储和累加。
设想,使用app_key+msg_id作为key,目标/送达/在线/第三方的目标/送达等作为field,然后通过这些key和field进行做累加!
一、内存占用测试:
1亿条app_key+msg_id做测试
用1,2,3,4,5等数字作为field表示目标、送达、在线等
在只有一个1field的情况占用了19.64G的空间,如果是17个field的情况占用了30G,也就是说,额外的16个field只增加了10G的空间!

如果以每天4亿条app_key+msg_id的量,保存4天的情况,大概需要的内存为:4*4*30*2(主从备份)=960G,这种情况能够让目前的CB存储减少一半以上,同时在report api读取每个msg_id的指标能从之前的20次以上变为只访问一次,极大的减小了对存储的访问。
未来再进行增加指标的时候,也能够减少内存的使用。
二、性能测试
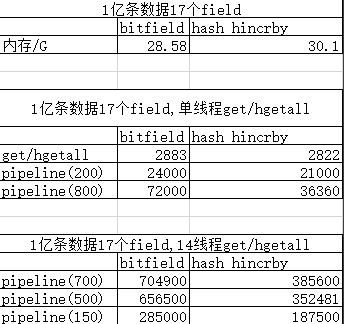
pipeline(150)表示的是使用pipeline进行提交,每次提交的量为150,其他以此类推!
bitfield使用的是u32,17个field,hash hincrby使用的field为‘a’,'b','c',后续可以使用0,1,2,3,4来进行代替!

检测当前report api的请求,发现峰值为6W每分钟(QPM),平均每秒1000个,即使以每条请求带有最大值msg_id数100来算,每秒请求redis的量为10W,根据上面测试的两种方案,在现有测试集群下都能满足对应的读写性能。
三、测试结论
结合当前业务情况与bitfield和hash 的hincrby的自身特点,建议使用hash的hincrby来进行做存储,建议理由如下:
当前业务中一条数据带有的field其实是不定,1-32个不等,其中很大一部分field可能不到5个甚至只有2个。使用bitfield方案存在定长的情况容易造成空间浪费,同时该方案只能增加field不宜删减field,读取的时候需要进行反向解析,整体不利于后期的维护。
而hash的hincrby可以根据实际的情况设置field的个数和值,避免一些干扰项,同时使用方便利于后期的维护!
另外在实际的生产中hash的hincrby使用的空间会比bitfield少!
四、实际优化效果
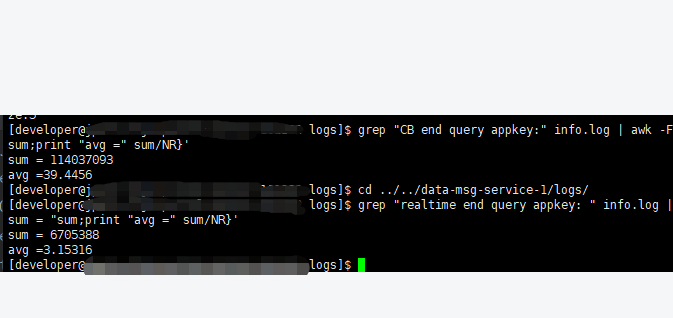
通过日志记录的调用延迟数据统计,使用redis hash替代CB后,请求后端的平均返回时长从39s下降为3s,效果十分明显。