【阅读笔记】网络之TCP拥塞控制算法BBR
原文链接:https://blog.apnic.net/2017/05/09/bbr-new-kid-tcp-block/
标题:BBR, the new kid on the TCP block
阅读时间:2019年9月
参考链接一:https://blog.csdn.net/dog250/article/details/52895080
参考链接二:https://www.ietf.org/proceedings/97/slides/slides-97-iccrg-bbr-congestion-control-02.pdf
参考链接三:https://queue.acm.org/detail.cfm?id=3022184
核心理解:
整个传输线路有三种状态:空闲(包来了马上得到处理)、排队(处理不过来了,先放到队列里面等着)、丢包(队列都塞满了,只能丢弃);
Reno和CUBIC实际上是一类(AIMD):他们最大的特点(或者说是缺陷)是把丢包当做拥塞。Reno使得传输线路在上面三种状态间来回切换;CUBIC也类似,但是相比Reno,CUBIC让传输线路较少处于空闲状态,也因为如此,CUBIC会导致延迟的增加,因为充分利用了排队功能。
Vegas和BBR是另外一种尝试,它们努力让传输线路一直维持在即将开始排队但是还没排队的状态。它们重点依赖对RTT的计算,而不像Reno和CUBIC主要依赖对ack包的追踪。
BBR有一个最大的特点,就是不直接把丢包当成是拥塞。在5%以下的丢包,BBR几乎不错出反应;在5%-20%只做很小的反应;只有在丢包达到20%以上时,BBR才会吧传输速度降下来。
Vegas传输速度也是线性恢复的,这一点和Reno类似。另外一个问题在于,Vegas在开始排队时就开始回撤,如果同一个线路上有类似Reno的session也在跑,因为Reno需要等到丢包了才会回撤,所以整个线路都会被Reno挤占掉。
BBR与Reno和CUBIC共处,从报告上来讲,容易挤占CUBIC的空间。具体与queue设置、Bandwidth Delay Product、RTT等相关。
部分重点内容摘要:
一、IP层只管发送网络包,但是把管理数据流(包括检测和修复丢包、管理数据流量)交给传输层的协议(也即TCP协议)。
二、TCP并不是一个固定的协议,TCP怎么管理数据流,怎么检测丢包并做出反应,是有很多的实现的变种的。
三、Reno流控制算法,基于ACK反馈,它的特点在于:
对out-of-order的ACK反馈包的反应比较敏感(会把发送速率降低到原来的一半)。
在带宽比较大的情况下,在降速之后再恢复回原来的带宽利用率耗时较长(10G带宽+30msRTT,需要3.5小时才能让带宽从5G提升到10G)。
Congestion Avoidance理论上会一直增加(每个RTT增加一个segment),最终会导致out-of-order ACK反馈的发生,所以最终会导致类似锯齿状(sawtooth)的带宽使用情况。
如果发生丢包导致的timeout的情况,Reno就丢失了整个流控制的ACK反馈信号,只能重新开始整个session的管理(slow-start)。
三、BIC及CUBIC流控制算法:
- BIC基于二分查找算法(binary chop)来从out-of-order的ACK反馈中恢复发送速率。
- BIC有一个最大的常量限制,而且一般比Reno算法固定的一个segment要大一些。
- BIC在低RTT网络环境下,表现得非常的激进(很容易在短时间内又超过上次碰到的最大值),BIC使用指数函数(exponential function)来管理这个流的发送数据大小。
- CUBIC是BIC的一种改进,它使用三阶多项式函数(third-order polynomial function)来管理流数据大小。
- CUBIC对out-of-order的ACK反馈,回撤程度比Reno小,而且能更快地恢复到原来的flow rate
原文链接:https://blog.acolyer.org/2017/03/31/bbr-congestion-based-congestion-control/
标题:BBR: Congestion-based congestion control
阅读时间:2019年9月
说明:文章本身就是一篇阅读理解
核心摘要:
BBR降低了网络的RTT,全球平均降低53%,在发展中国家降低80%。(主要是因为它尽量避免使用queue)
传统的loss-based congestion control(比如CUBIC)的问题主要在于:把packet loss和congestion等同起来了;而现在这个两个事情并不能简单的等同起来。
对TCP的性能来讲,重要的几个概念:
- round-trip propagation time (RTprop)(在没有queue的情况下的RTT)
- bottleneck bandwidth, BtlBw (the bandwidth at the slowest link in each direction)
- Bandwidth Delay Product (BDP) _is the maximum possible amount of data in transit in a network, and is obtained by multiplying the bottleneck bandwidth and round-trip propagation time.
网络的最佳运行点(optimal operating point)在于:刚好在BDP的阈值;而loss-based congestion control算法则运行在BDP+bottleneck buffer
BBR追踪两个基本的数据:bottleneck bandwidth and round-trip propagation time
BBR每8个RTT周期,会控制传输速度为当前已探测的bottleneck bandwidth的1.25,0.75,1,1,1,1,1(倍数),主要是用来探测是否有更高的传输速率的可能性(比如线路情况变化了)。
BBR相对CUBIC,对于2G、3G等网络降低用户的延迟非常有帮助(延迟本身主要是因为手机-SGSN (serving GPRS support node)直接的buffer导致,150KB-10MB)。
原文链接:https://queue.acm.org/detail.cfm?id=3022184
标题:BBR: Congestion-Based Congestion Control
副标题:Measuring bottleneck bandwidth and round-trip propagation time
参考链接:https://tools.ietf.org/id/draft-cardwell-iccrg-bbr-congestion-control-00.html
核心理解:
当前TCP网络慢的主要问题在于:把packet loss理解成了congestion,这在1980s那个年代是对的,因为技术条件的限制。
目前loss-based congestion control算法(例如CUBIC),在buffer很大的情况下,会引发bufferbloat问题(delay比较大,delay的jitter也比较大);在buffer很小的情况下,会误把丢包当做congestion,导致较低的吞吐量。
TCP传输三大限制常量:RTprop(管子的长度),BltBw(bottleneck bandwidth)(管子中间的最小直径),bottleneck buffer。
因以上三个限制,引发传输的三个阶段:app-limited(应用不够快),bandwidth-limited(处理不过来了,但是buffer还有空间),buffer-limited(不但处理不过来,而且buffer也被占满了)。
大的buffer可以是BDP(BDP =BtlBw × RTprop)的几个数量级大小,可能导致增加数秒的RTT,从而增加整个延迟。
通过测量这两个参数(bottleneck bandwidth and round-trip propagation time, or BBR):从不确定性中(ambiguities)寻找到Kleinrock's optimal operating point。
当管道100%利用的时候,并不意味着没有queue(比如第一次发送10个包,然后稳定地发送5个包,刚好管道的速率也是5,那么就会保持一个永远不能消失的5个包的队列),进而导致delay。
由于对buffer的使用情况不一样,短的连接和请求(比如request/response的类型连接)适合探测真实的RTprop,但是却无法获知BtlBw;大数据量、持续时间较长的连接适合探测BtlBw,但是却无法获知真实的RTprop(除了开始几个RTT数据之外)。
pacing_gain是BBR的最重要的调节参数;会以BtlBw x pacing_gain的速率来发送。
BBR分为四个阶段:STARTUP,DRAIN,ProbeBW,ProbeRTT;大部分的时间会花在ProbeBW阶段;
1、STARTUP:当BBR发现在三次尝试double传输速率时,但是实际上增加的量小于25%,则认为管道满了,退出STARTUP阶段,进入DRAIN阶段。详细参考:Startup
- 这里和CUBIC的slow-start的核心区别在于:slow-start是基于丢包才停止的,而BBR是基于对带宽增长的停滞而退出这个阶段。详细可参考这个PDF文档的33页。
2、DRAIN:主要是释放掉在STARTUP阶段造成的queue,以降低后续的延迟;它的pacing_gain是STARTUP时期的倒数。
3、ProbeBW:每8个RTT周期,会控制传输速度为当前已探测的bottleneck bandwidth的1.25,0.75,1,1,1,1,1(所谓的pacing_gain,即倍数),主要是用来探测是否有更高的传输速率的可能性(比如线路情况变化了)。
4、ProbeRTT:每隔几秒会进入一次ProbeRTT阶段,它在至少一个RTT时间长度期间,把inflight包降低到4个,然后恢复来的状态;这一阶段主要是释放出queue,让其他的flow能探测到真实的RTprop数值,而当其他flow发现新的RTprop值时,也会触发进入ProbeRTT阶段。目的主要是保证公平和稳定。
CUBIC只能一直增加,直到丢包发生或者接受者的inflight limit(receiver window size),才停止增加传输速率。
20190918:
真正能够让自己彻底理解某个东西的,还是第一手的资料;看他人加工过的资料,是一种帮助和捷径,但是很多时候仍然无法替代亲自阅读第一手资料。
我阅读BBR相关资料,发现真正能把原理说清楚的还是IETF描述文档和作者们的原始发布文档。
BBR存在的问题及改进方法:参考 https://datatracker.ietf.org/meeting/102/materials/slides-102-iccrg-bbr-startup-behavior-00
- 大量的flow没有退出过STARTUP阶段。降低pacing gain,从2.89降低到2.
- DRAIN阶段的pacing rate太低,时间太长。
其他参考链接:
Making Linux TCP Fast 文章介绍了BBR、TSO、Pacing等发送端的优化方案。
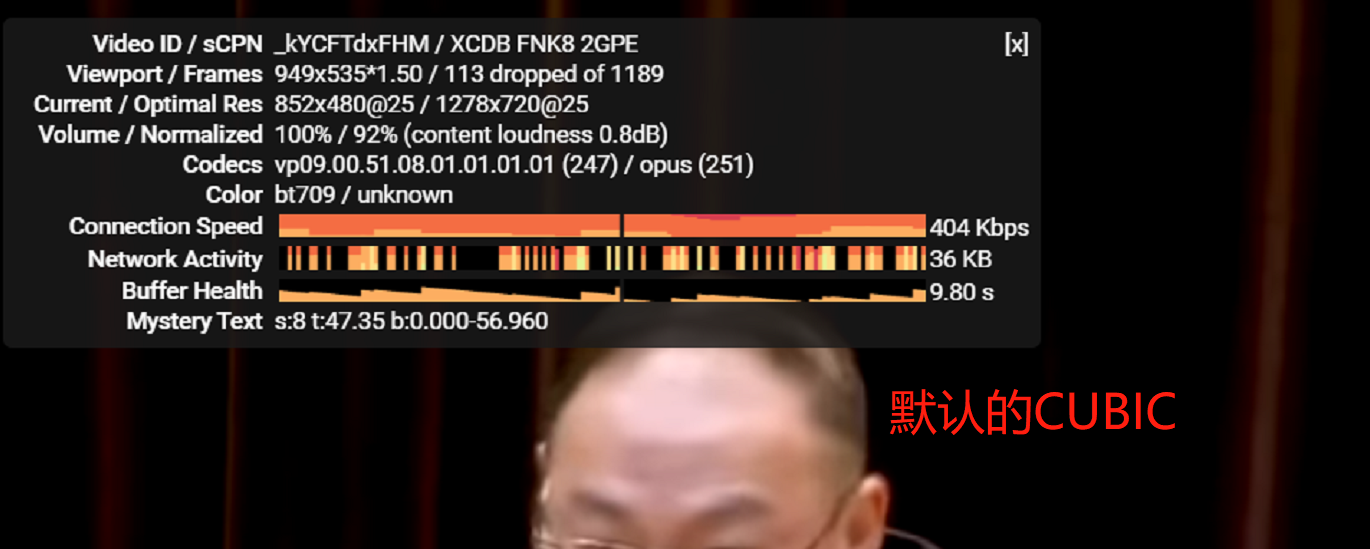
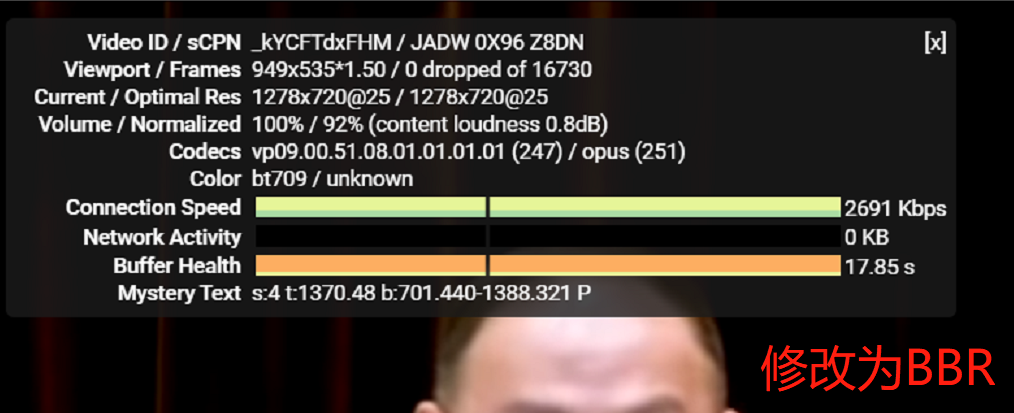
验证真实效果
BBR对比CUBIC实际效果,速度上去了5倍,有质的改变:
环境:Amazon Linux 2;
测试时间:2019年9月;
本地网络环境:中国电信200M光纤入户;
区域:新加坡;
uname -a
Linux ip-xxx.ap-southeast-1.compute.internal 4.14.123-111.109.amzn2.x86_64 #1 SMP Mon Jun 10 19:37:57 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
默认是cubic,使用以下命令修改为bbr,断开并重新连接:
modprobe tcp_bbr
modprobe sch_fq
sysctl -w net.ipv4.tcp_congestion_control=bbr