运维能力第一阶段--满足业务需求
业务交到手上,自然是有各种需求的,满足业务的各种需求,是对运维最基本的要求。
先解决有无问题,再从效率、质量、成本和安全等方面进行迭代和提升。
一:满足业务对资源需求的能力
业务对资源的合理需求必须得到满足,保证质量和效率的同时需要控制好成本。
主要从以下三个方面考虑:
效率:同样的资源需求,多久能得到满足,一个月、一个星期、一天或者2小时,对业务部门来说是有质的区别的。
质量:给出来的资源质量如何?是否符合预期?前后一致性是否有保障?
成本:成本可以增长,但必须是可控的。
1.1、使用物理IDC机房,租赁机柜和带宽,自己购买服务器
优势
- 机器配置和网络架构更加自主可控
- 物理隔离更安全
- 可选择部署地域更广
- 性能可预期
- 上规模时成本有优势
劣势
- 交付周期长
- 防攻击抵御能力差
- 可伸缩性比较差
选择物理机房的技术准备
远程管理卡和远程管理网络
系统安装服务,如FAI、PXE、Cobbler等
网络上联出口高可用
服务器网卡设置bonding
公网互联互通,考虑出口线路
1.2、直接租赁专用物理服务器
优势
- 交付周期相对较短,一般在几小时或者几日内能交付
- 具备一定程度的可伸缩性,一般按月租赁,退租方便
劣势
- 成本偏高
- 知名的厂商有:Softlayer、RackSpace、NTT等
1.3、选择传统物理IDC机房方法
看机房建设标准
比如国内机房有所谓三星、四星、五星机房,国外有Tier-2,Tier-3,Tier-4等,理论上级别越高机房越可靠。
看机房地理位置和建筑外形
优先选择地理位置在郊区、独栋的专业IDC机房,这些一般比处在市中心、高楼大厦中划分某几层用来做IDC的要好。
选择知名的IDC机房供应商
比如选择Equinix、Digital Realty、NTT等提供的机房,一般机房本身的品质有保障。
这里可以重点关注一下Equinix机房,他主推的IBX服务,机房质量和网络的互联互通都比较好。
更多关于IDC选择的标准,可以参考UptimeInstitute。
1.4、选择云服务厂商
云服务厂商用得越来越多,我们也可以充分利用其优势和特点,帮助我们支持好业务的运行。
优势
- 资源和服务获取速度快
- 可伸缩性强
- 降低服务使用的技术门槛
劣势
- 安全不可控
- 性能不可控
- 排查问题存在黑盒
AWS
云服务领域的绝对老大
使用过的特色服务:
Lambda:无服务器运行环境
Athena: Hive as a Service
S3:近乎无限可扩展的对象存储服务
需要注意的地方:
AccessKey的安全性要注意,不建议使用,一旦泄露影响非常大;建议使用IAM和MFA管理用户权限
EC2存储区分持久存储和临时存储,临时存储在关机-再开机后数据全部丢失
EC2实例默认不能转发数据包,需要后台设置运行转发
注意各种资源的购买限制,如果没规划好,突发需求可能不能马上得到满足
阿里云
国内云服务的领导者
使用过的特色服务:
高速通道
需要注意的地方:
管理后台用户体验极差,一般建议自己通过API自定义UI,但是API很不健全
ECS实例里面有自动运行阿里的多个agent,安全性和可靠性有待考量
1.5、CDN服务
一般来讲,现在的企业都不会自己建设CDN,一般选择外包给专业的CDN服务商。
Akamai
老牌CDN服务商,全球CDN及相关服务的老大,绝对的技术领头羊和市场领导者
优点
网络覆盖好,接入ISP达到1700+,用户体验好,防攻击能力强,可配置性极强
缺点
服务较差,费用比较贵,后台配置麻烦,刷新缓存(Purge)比较慢
AWS CloudFront
亚马逊云服务的一个产品,近年来表现不错,持续扩张中
优点
后台配置简单,即开即用,和AWS其他服务结合紧密
缺点
并非专业的CDN厂商,节点覆盖不多,全球节点不到100个,可配置性较差
CloudFlare
这些年新出的一个CDN厂商,大量使用anycast技术,主打高性能、低价和防攻击,占领了大量中小企业市场
优点
费用较低,企业级套餐可能只有Akamai的三分之一价格;配置比较简单方便;刷新缓存(Purge)极快
缺点
回源模式单一,不支持源站+子目录形式回源;
CDN管理需要考虑的问题:
带宽和流量异常告警
源站的高可用和上传访问控制
1.6、DNS域名解析服务
DNS服务往往容易被人忽略,但是其实DNS服务是非常核心的服务,也是比较脆弱的服务,容易成为攻击的目标
自建DNS服务
安全性方面需要考虑一下问题:DDOS,DNS放大攻击,zone transfer访问控制,高可用
功能方面:智能DNS功能,分布式访问性能
DNSPOD
国内知名的DNS域名解析服务提供商,有免费版但不保证可用性,经常用来当小白鼠测试新功能;企业版比较不错,各种运营商线路以及国内外区分,基本满足国内业务的需求。
提供HTTP DNS服务,可有效避免DNS拦截。
AWS Route53
支持智能DNS,对海外国家/地区区分较好;有CNAME flatting等功能。
Akamai FastDNS
功能比较单一,没有智能DNS功能。
有一个问题:不支持同一个域名修改record类型,只能删除再添加,会导致服务短暂中断。如:www.mysite.com CNAME 到 mycdn.akam.net,需要修改成 A 记录并指向 IP 1.2.3.4,只能删除原有CNAMEA记录记录再重新添加,不能直接修改记录类型。
1.7、容量(能力)管理
从ITIL中的Capacity managememt而来,是资源规划的是否有效的方法。
容量管理主要需要考虑一下几个方面:
业务预算搜集
- 业务资源趋势判断
- 新增业务资源搜集
资源池管理
- 业务日常资源
- 业务突发资源
- 特殊故障资源
二:满足业务发布/变更的能力
运维不能成为阻挡业务发布和变更的障碍
- 效率: 自助操作
- 质量: 流程化/规范化
2.1、发布系统
无论是自己开发还是使用开源工具,一套可以交付给业务人员进行操作的发布系统,确实是必须的,不然运维就会被日常需求困住收缴,而响应时间也会影响业务的效率。
比如业务想更新一下Web的代码,叫运维操作的话,运维也只是一个劳动力而已,操作本身没有任何体现价值的地方。如果把同样的工作做到发布系统里面,设定好相应的流程和权限,让相关人员自己操作,大家都满意。
2.2、持续集成和持续交付
持续集成工具,对于减少运维和开发的重复劳动,提高工作效率能起到非常重要的作用,还能保证交付质量。比如从代码管理工具(SCM)中的代码提交、代码单元测试、功能测试、打包、推送相关环境都做成自动的,对于效率的提高可想而知。
一般开发团队都有自己的CICD工具和流程,运维可以考虑把CICD应用到测试环境的管理上来。
常见开源工具:
Jenkins
Spinnaker
2.3、作业系统
作业系统,或者叫事件驱动系统(Event-Driven Automation),能够基于事件、时间等自动或者手动进行固定化流程的操作。
重点提升的是质量和效率:把可以交给别人做的事情放心地交出去,把经常需要做的事件固化下来。
比如我们要重启某些服务,可能需要按一定的顺序操作,那么我们可以把这个工作固化成一个作业交付给相应的业务人员。对方需要做操作的时候,可以直接在作业系统上点击操作,运维完全不用参与,提升质量和效率。又或者一些常见的操作,比如清理日志或者获取机器信息,可以把这些固化到作业系统,需要的时候只需一键点击,不用担心前后操作的不一致。
常见开源工具:
RUNDECK
StackStorm
三:快速获取业务相关信息的能力
有异常能发现,能快速获取想要的数据,能快速定位问题
效率: 自助化/可视化/用户体验 基础设施既代码 配置管理 文档
质量: 多维度监控覆盖
屏蔽复杂度,给需要数据的部门/业务,提供统一的获取数据的接口
基础监控
把最基础的数据统一搜集起来,无论是什么类型的服务器,无论运行什么服务,这些都是有价值的、或者都需要查看的数据。可以做成统一的模板。
通过salt+zabbix+python+graphite+grafana,基本可以把一套基础监控的环境自动搭建和维护起来。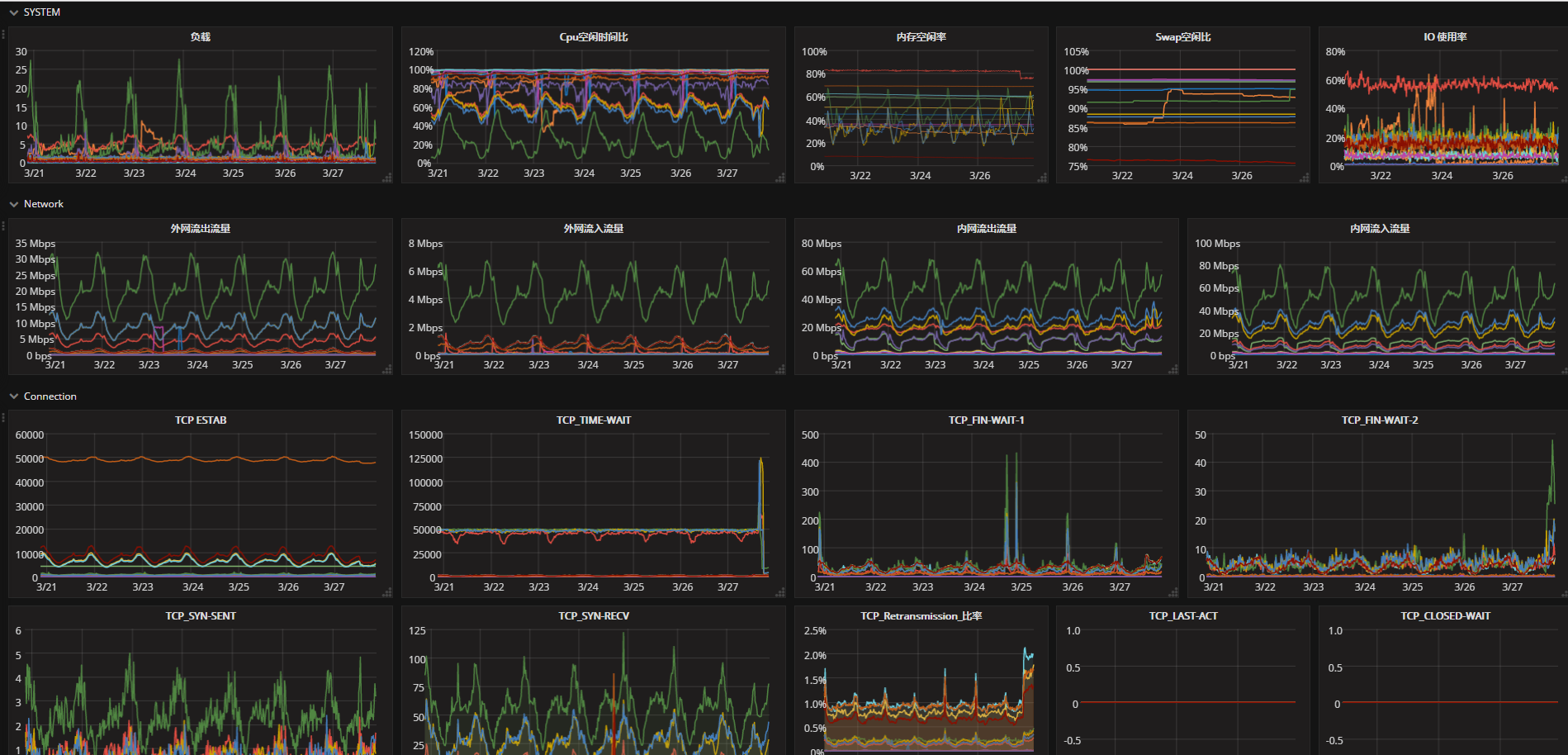
网络监控
对网络质量的监控同样非常重要,对延迟、丢包的变化需要特别注意;对业务服务对象所在地区的网络情况要区别对待,比如四川麻将业务,则重点关注川渝地区。
基于smokeping+python+graphite+grafana,数据搜集、上报、展示一条龙全部解决。
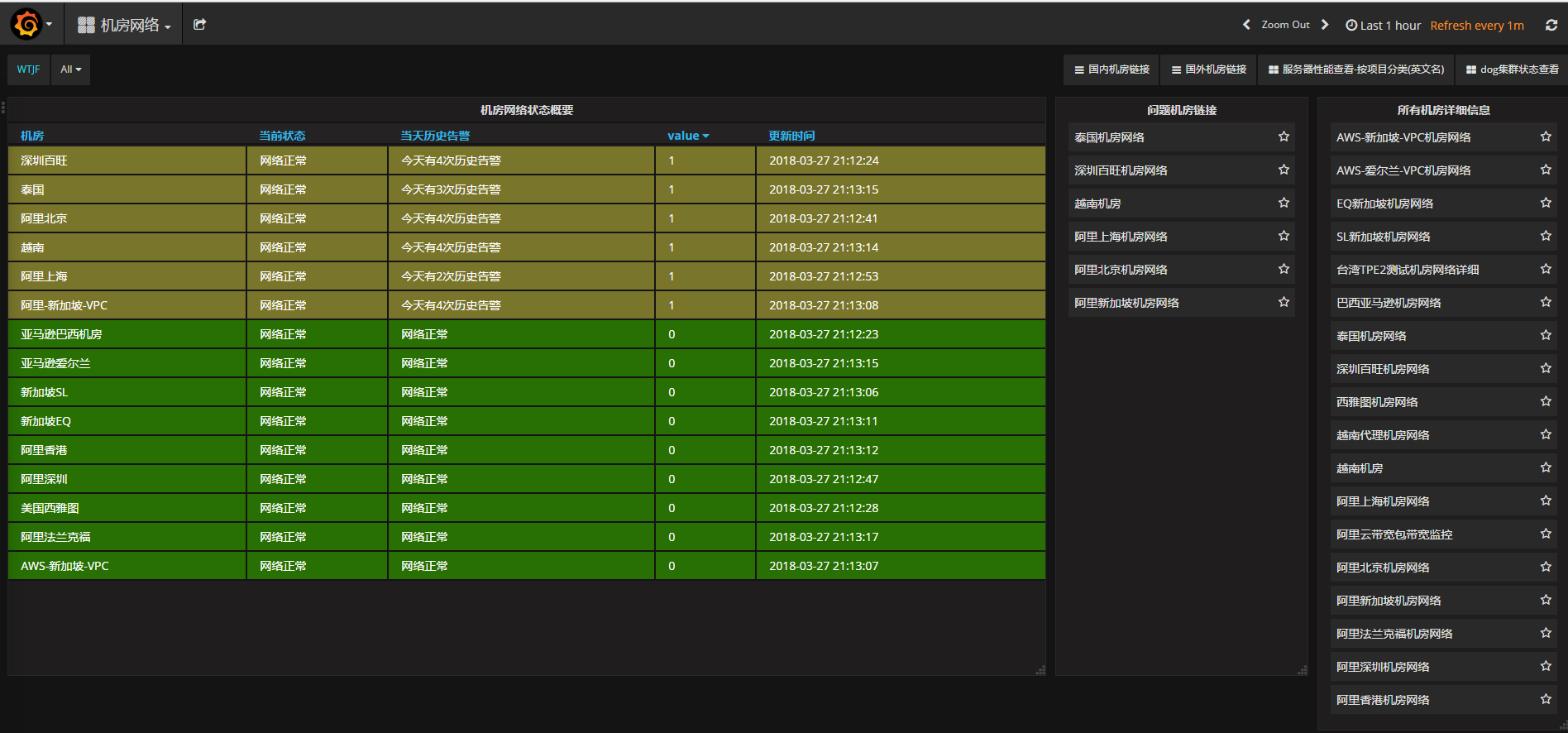
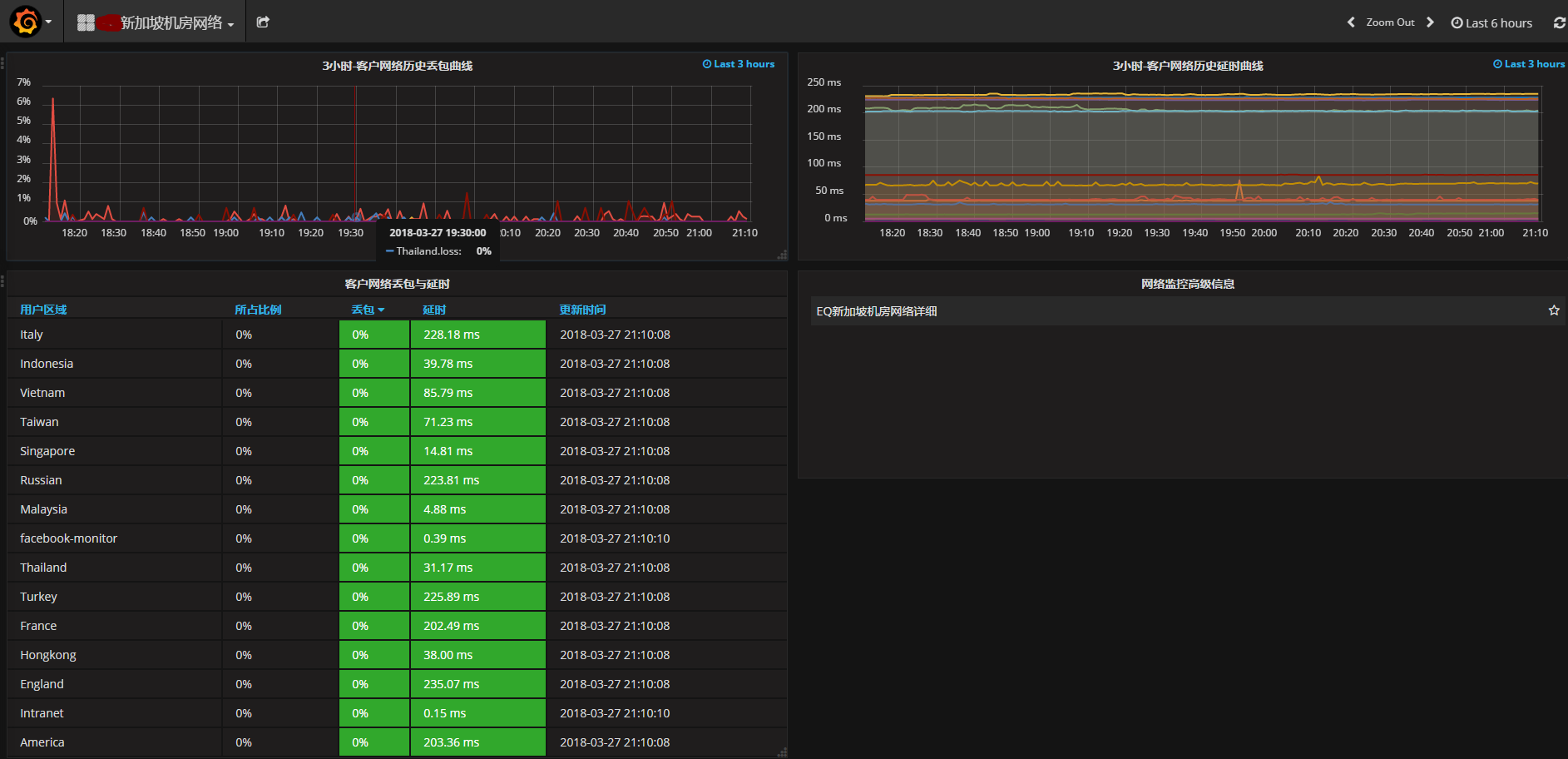
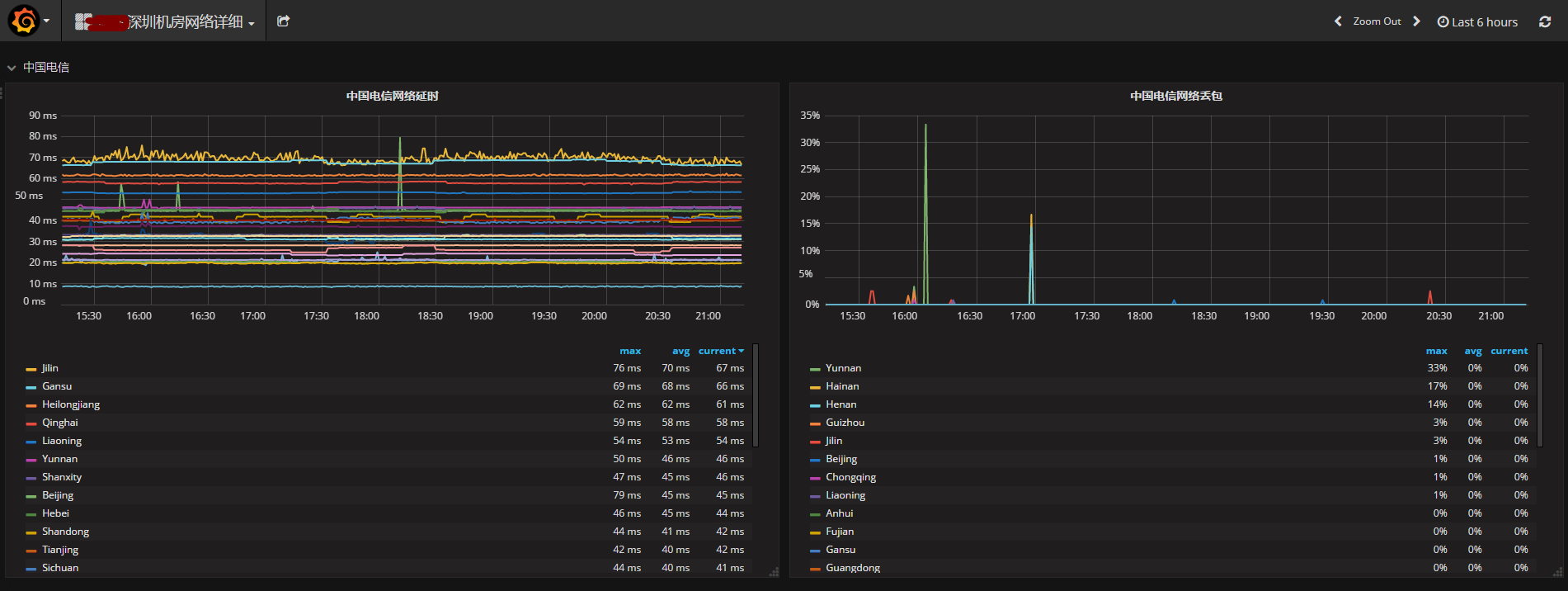
网络监控的痛点在于:如何获取稳定、可靠的目标监控点,我有一些经验可以分享:
- 找当地排名靠前的网站的IP地址,比如通过Alexa按国家和地区查找。
- 查找当地公共的DNS服务器,这种一般很少变动。
- 通过traceroute用户的真实IP地址,监控中间出现频率较高的公共节点,这种一般是ISP的网关或者路由设备,比较稳定。
应用基础指标监控
业务在运行中,必然有一些技术指标需要搜集,比如php请求数、haproxy连接数、缓存命中率等等。这些数据都需要根据业务的具体情况进行监控。
使用Prometheus+grafana+相应的exporter或者python脚本自定义的的上报内容,可以很好地实现。
比如我们的php应用监控页面:

应用性能监控
Application Performance Monitor(APM)
做APM是深入优化业务的一种关键技术,可以从业务内部逻辑上做很多的数据统计,对于排查问题以及优化性能起到非常大的帮助。
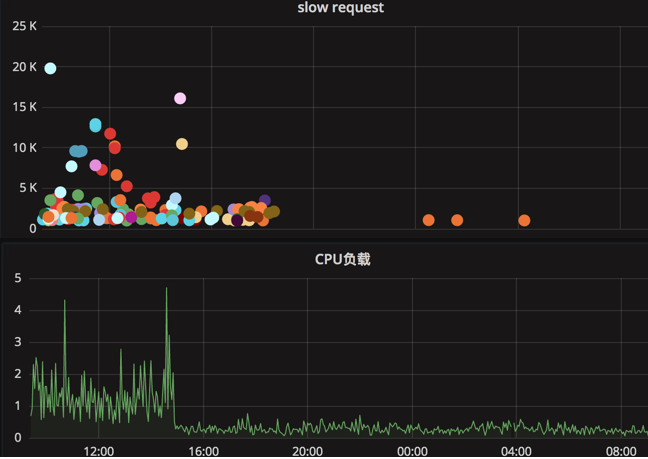
我们使用了Statsd+Graphite+Grafana的方案,业务端插入相应语言的上报代码,对于函数的调用次数和延迟做到实时监控。使用Statsd的方案,主要是因为它基于UDP上报,几乎对性能不产生影响,上报异常也不会对业务产生不良影响或影响很小。

经过有针对性的优化后,性能明显提升:
业务指标监控
比如在线人数、订单数量、比赛场次、充值金额等等,一旦有异常情况,比如在线人数比昨天下降超过20%,可以及时发现并报警。
日志管理和分析
不管是系统还是应用,都会产生大量的日志,可以把这些日志收集并处理,提炼出有价值的数据。
常用工具集:
ELK
Splunk
调用追踪系统
可以更好地看到内部函数、进程之间的调用关系和延迟信息,方便业务的性能优化等,需要业务配合修改代码。
常见开源工具:
OpenTrace
OpenZipkin
知识管理系统
把业务相关信息、操作规范和流程、故障历史等等,都通过知识管理系统统一管理起来,沉淀下来,不但利于快速处理问题,人员交接和新人培训也要方便很多。
常用工具有:
Confluence
DokuWiki
四:满足业务对可用性和稳定性要求的能力(SLA指标)
默认一切都是不可靠的,都是会出故障的,以此为基础前提来努力提高业务的可用性和稳定性
核心关注点:
- 质量: 去单点 故障自愈能力 安全规范和扫描
- 效率: 服务自动伸缩 自动恢复和自动迁移
架构高可用
硬件上的故障很难避免,那么就需要从业务架构上考虑这个问题,从一开始设计业务架构的时候,就需要考虑到底层基础设施的不稳定性。比如典型的LNMP的架构模型,WEB层可以使用LVS+keepalived确保高可用,数据库也可以使用keepalived做主从加高可用。
服务自动恢复
主要概念:微服务、服务注册、服务发现、服务编排
最简单的:也可以通过判断业务逻辑是否正常来做一些自动化的操作,比如业务端口不通了,则自动将相应的进程拉起。
如果某一个硬件故障了,是否能自动恢复呢?比如直接把故障机器上的服务迁移到其他正常的机器。
又或者,有一个调度工具来帮我调度管理应用在哪些机器上运行,我只需要告诉他运行什么东西就行了,至于在什么地方运行,故障了迁移去哪里,都由这个调度器来决定。
常用开源工具:
Docker Swarm
Kubernetes
安全
安全是一个大的话题,但是我把安全归纳为:可控。不是谁想干啥就能干啥的,都要按照既定的规则来操作,违规操作不能生效,而且被查出来还要被处罚。
如何确保业务安全运行,如何发现泄露在外的漏洞,意外开了一个不安全的服务怎么办?网络防火墙失效了怎么办?安全是一个很严肃的问题,如果你不太懂安全,可以参考一下OWASP,至少能对安全有一个基本的把握。
安全防护体系应该包括以下几个方面
网络层访问控制:对服务器的访问控制,应该从网络上进行限制,一个是把控制前移,避免影响服务器性能;二是防止系统管理员的违规或者误操作,导致服务器意外对外暴露。可以是在交换机上进行控制,也可以是虚拟的网络安全组等工具。把不相干的流量和访问挡在外面。
主机防护体系:包括tcp-wrappers+iptables做第二层访问控制,SSH登陆堡垒机,history操作记录需要永久保存,syslog需要永久保存等。
网络安全扫描工具:自己把自己当做攻击对象,能提前发现和解决问题,常用工具有:
Nessus
OpenVas
nmap
五、快速部署和故障恢复的能力
故障演练和预案
凡事预则立不预则废
机房断电了怎么办?机房网络波动怎么办?机器意外死机了怎么办?当你面对这些问题的时候,你是临时去想方案么?这样肯定不行,一个运维团队,没事就要考虑考虑这些问题,时不时模拟一下,然后把解决的方案整理记录下来,一旦真的发生了这种类型的问题,照着流程走就行了,不慌不忙。
基础设施即代码
Infrastructure as Code,是最近比较流行的一个技术概念。
想象一下一个场景:你需要把你在亚洲部署的一套复杂的业务架构,在美国部署一遍,今后还可能在其他地区部署,而且可能要时不时增加或者减少资源。如果是人工去维护这样的基础设施,复杂度和效率之底下可想而知,而且不利于持续的跟踪和维护。而“基础设施即代码”工具,可以帮助抽象定义这些资源,比如网络、防火墙、机器、负载均衡器等等。当然,现在这些工具,主要还是针对公有云场景比较多。
常见的“基础设置即代码”工具有:
CloudFormation
TerraForm
配置管理工具
很难想像手工配置服务器和应用,一般建议使用配置管理工具来做
常见配置管理工具:
Ansible
SaltStack
系统镜像和模板
一般用在虚拟机环境,方便快速启动大批虚拟机,节省时间
备份与恢复
这个不用强调太多了,全备份、增量备份、异地备份、备份文件的管理、备份可用性验证等等
不可变基础设施
这是业界比较新的理念,基础设施被做成不可变更的,从根本上杜绝人工上去修改配置的可能性。
比如你需要一台服务器,从镜像安装好之后,就是业务需要的样子,不需要做任何额外的配置。如果有故障,直接找另外一台机器替换掉。这样可以从根本上避免掉配置管理的工作,避免手动ssh上去做任何配置的操作的可能性,对于环境交付的一致性能起到很好的保障作用。
而且,由于基础设置的不可变性,在发布新镜像前,都会更加谨慎地做好测试工作,能更进一步提高镜像的稳定性。